Kjør Llama på din Raspberry Pi 5 uten å bruke Ollama
I dette innlegget deler jeg mine erfaringer med å sette opp en AI-chatbot på Raspberry Pi 5, hvor jeg navigerte gjennom tekniske utfordringer og løsninger. Dette er en praktisk guide for de som ønsker å utforske AI og Raspberry Pi, og tilbyr en steg-for-steg gjennomgang for å få en offline chatbot til å fungere.

Så jeg har drevet og fiklet med min Raspberry Pi 5 8GB siden jeg fikk den i desember. Jeg fant mange veiledninger for å installere en LLM på den, men støtte stadig på problemer som jeg ikke lett kunne komme forbi. Mye av dette hadde å gjøre med datamaskinen jeg skulle bruke til å hente/bygge/kvantifisere LLM-en på, og noe av det hadde å gjøre med at jeg ikke klarte å installere alt jeg trengte på min RPi5 uten å støte på problemer.
Det er derfor jeg skriver denne veiledningen, hvor jeg peker på hvor jeg stakk fast, og skriver hvordan jeg jobbet meg rundt dette.
Så dette er på ingen måte en veiledning som jeg har funnet ut helt på egen hånd (jeg er ikke ekspert på noen av disse temaene), men mer en veiledning som skal hjelpe i tilfelle noen sitter fast.
Jeg brukte hovedsakelig DENNE VEILEDNINGEN av Marek Żelichowski som jeg fant på LinkedIn, og har lagt til stegene jeg trengte for å få det til å fungere på mine egne enheter. Jeg vet at han sier nederst i bloggen sin at det er et resultat av innspill fra flere personer/kilder, men kreditt bør gis når det er fortjent, og hans veiledning var en av de få som fungerte for meg og som ikke krevde Ollama.
Jeg har prøvd å gi kreditt der kreditt skyldes (lenker til eksterne innlegg og sider), men hvis noen kreditter mangler, vennligst gi meg beskjed, så vil jeg gjerne legge dem til. Nå, la oss fortsette!
Hva trenger vi?
- Kilde-PC med enten Windows eller en Linux-distribusjon for å hente og kvantisere LLM(ene)
- 8GB Raspberry Pi 5 for å kjøre LLM på
- Et minnekort med minst 32GB som inneholder et forhåndsinstallert OS som Raspbian (Jeg personlig bruker Ubuntu 23.04 på min RPi for dette)
- En USB-pinne med minst 22GB ledig plass for å overføre LLM fra kilde-PCen til din RPi
Forberedelse av kilde-PCen
Vi starter på vår (Linux-baserte) kilde-PC. Siden jeg ikke eier en og ikke hadde lyst til å bry meg med dobbeltoppstart eller å installere om PCen min med en Linux-distro, bestemte jeg meg for å bruke "WSL". Dette er en innebygd Microsoft-funksjon som gjør at vi kan kjøre Linux-distroer direkte fra vårt Windows-miljø. For de som allerede jobber på en Linux-PC, er kanskje de følgende stegene ikke nødvendige.
For å installere WSL:
Merk at jeg brukte DENNE VEILEDNINGEN for å sette opp WSL på min Windows PC.
Først, kjør PowerShell som administrator. Vi gjør dette ved å høyreklikke på PowerShell og velge alternativet "Kjør som administrator". Du må kanskje fylle inn ditt admin-passord for å gjøre dette, avhengig av hvordan sikkerheten på maskinen din er konfigurert.
I PowerShell-vinduet som åpnes, kjør følgende kommando:
> wsl --install
Dette vil installere Ubuntu som systemet du skal arbeide med. Alternativt kan du velge en spesifikk Linux-distribusjon som kan installeres direkte ved hjelp av WSL ved å bruke kommandoen
> wsl --list --online
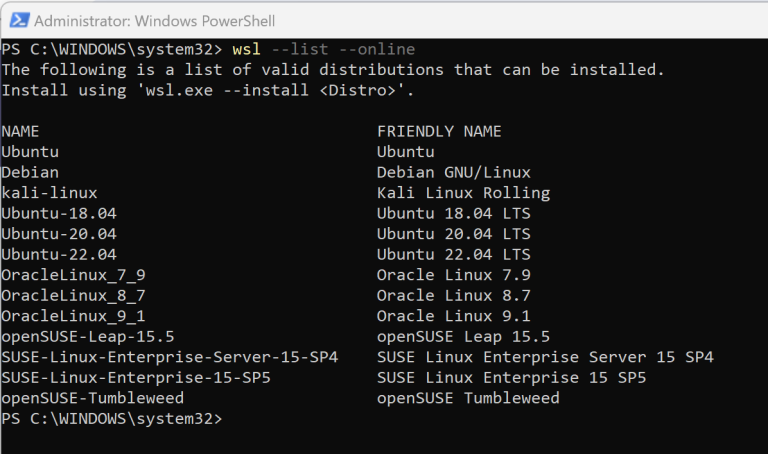
Velg distribusjonen du ønsker å installere og legg den til i din neste installasjonskommando. Jeg brukte standarden, men hvis du ønsker å kjøre Ubuntu 22.04, ville du bruke følgende kommando
> wsl --install -d Ubuntu-22.04
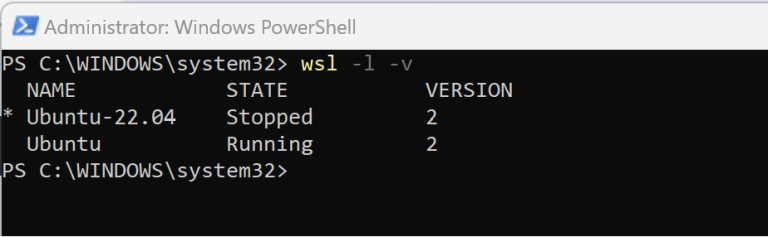
Etter installasjonen er gjort, kan du verifisere at den er installert med denne kommandoen
> wsl -l -v
Det anbefales sterkt å starte PCen på nytt etter installering av WSL. Etter omstarten kan din Linux-distribusjon finnes i startmenyen din.
Å åpne et av disse programmene vil åpne en kommandoprompt (CMD) der du kan kjøre kommandoer mot din Ubuntu-installasjon. Vi vil bruke disse kommandoene til å laste ned og bygge Llama-prosjektet, og for å laste ned og kvantisere en modell som kan kjøre på Raspberry Pi.
Konfigurering av vår Linux kilde-PC
Nå som vi har vår Ubuntu-installasjon oppe og går, eller hvis vi hoppet over de ovennevnte stegene fordi vi allerede kjørte en Linux-distro, er det på tide å begynne å installere avhengighetene vi trenger for å utføre stegene nedenfor.
Først og fremst ønsker vi å sørge for at systemet vårt er oppdatert
> sudo aptupdate
Deretter ønsker vi å installere Git, som er det vi vil bruke for å klone/laste ned Llama.cpp-prosjektet til vårt miljø
> sudo apt install git
Til slutt trenger vi å installere noen verktøy som vi trenger for å lage prosjektet og kvantisere LLM
> python3 pip install torch numpy sentencepiece
Merk at på dette steget har jeg stått fast MANGE ganger. Systemet mitt klaget stadig over 2 ting, som jeg nå vil forklare;
Pip kunne ikke bli funnet. For å unngå dette, måtte jeg installere Pip gjennom Python-pakken som en del av apt install
> sudo apt install python3-pip
Det plaget meg stadig med x509-feil, “self-signed certificate in certificate chain”. Uten å gå for dypt inn i dette, betyr denne feilen at det er noe galt med min nettverkskonfigurasjon, og jeg kan ikke komme gjennom. Jeg prøvde en rekke løsninger for å komme forbi dette, men fikk det aldri til å fungere. Problemet kan ha vært at jeg prøvde å gjøre dette bak en proxy eller brannmur, som gjorde det nær umulig å få konfigurasjonen riktig. Jeg endte opp med å bytte til et annet system som ikke hadde disse restriksjonene, og voila, alt fungerte som en drøm.
Viktigst, da jeg kjørte “python3 -m pip install” kommandoer, fikk jeg en feil som sa at jeg var i et “eksternt administrert miljø” og måtte bruke en slags virtuell miljø (venv) for å få alt til å fungere. Vel, jeg prøvde å bruke det, og det fungerte ikke for meg, så min løsning var å fjerne symlinken til det såkalte “eksterne miljøet”. Hentet fra DENNE INNLEGGET på stackoverflow, en kommentar på et av svarene;
> sudo mv /usr/lib/python3.11/EXTERNALLY-MANAGED /usr/lib/python3.11/EXTERNALLY-MANAGED.old
Nå som det er ute av veien, bør du ikke ha videre problemer med å installere avhengighetene gjennom Pip.
Til slutt trenger vi å installere G++ og Build Essential
> sudo apt install g++ build-essential
Nedlasting og bygging av Llama-prosjektet
For å laste ned Llama-prosjektet til vårt arbeidsområde, vil vi bruke "git clone"-kommandoen.
> git clone github.com/ggerganov/llama.cpp
Etter nedlastingen er fullført, vil vi gå inn i mappen vi nettopp lastet ned
> cd llama.cpp
Nå vil vi "make" prosjektet for å bygge de nødvendige filene for å kjøre våre modeller
>make
Mens dette kjører (eller etter det er ferdig), kan vi laste ned en av modellene som vi ønsker å kjøre på vår RPi5. Modellene kan lastes ned fra enhver kilde (som huggingface), men opplæringen jeg fulgte brukte en magnetlenke som kan brukes med en torrentklient. Jeg brukte QBitTorrent som klient, som kan installeres via
> sudo apt install qbittorrent
Etter at det er installert, kan du bruke følgende kommando for å åpne applikasjonen
> qbittorrent
Dette vil åpne GUI for torrentklienten. Nå kan du legge til en magnetlenke ved å klikke på "lenke"-ikonet, og lime inn følgende magnetlenke
magnet:?xt=urn:btih:ZXXDAUWYLRUXXBHUYEMS6Q5CE5WA3LVA&dn=LLaMA
Siden vi ønsker å prøve å kjøre vår RPi5 med 7B-modellen (de andre modellene er mye større og krever mye mer kapasitet), ønsker vi å velge kun 7B-mappen, samt filene under den (tokenizer.checklist.chk og tokenizer.model)
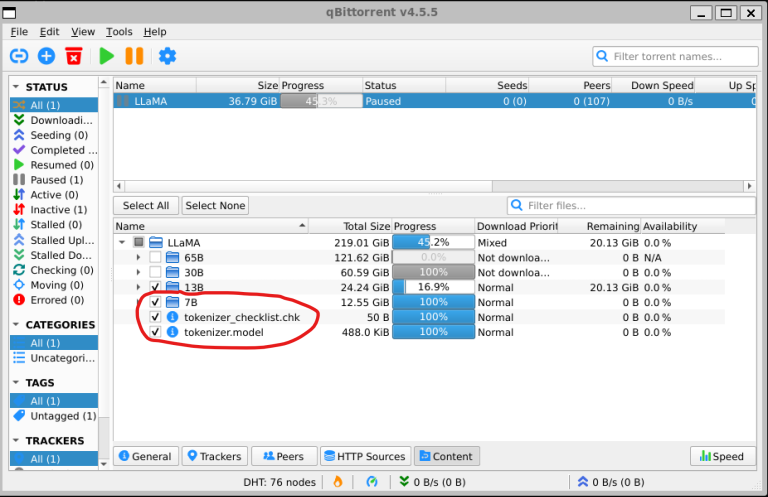
Når filene har blitt lastet ned, kopier dem til "llama.cpp/models"-mappen. Dette kan gjøres via kommandolinjen i en terminal, eller ved å åpne filutforsker-GUI. Følgende kommando åpner filutforskeren i gjeldende mappe. Du kan da lokalisere 7B-mappen og tokenizer-filene, og kopiere dem til llama.cpp/models-mappen.
> gio open .
Nå, før vi kan starte med å kvantisere vår modell for å gjøre det mulig å kjøre den på vår RPi5, må vi redigere en JSON-fil. Denne filen inneholder en verdi som vil føre til at byggingen av modellen krasjer. Det er usikkerhet om hvorfor denne verdien er i denne filen, ettersom løsningen er å bare justere et tall, og alt kjører problemfritt.
I llama.cpp/models/7B-mappen, finn filen “params.json” og åpne den. Jeg brukte VIM for å redigere denne filen.
> vi llama.cpp/models/7B/params.json
Etter å ha åpnet den med VIM, trykker du på “i” for å gå inn i innsettings- (redigerings-) modus. Rediger verdien “vocab_size” fra -1 til 32000. Når du er ferdig med å redigere, trykk på “ESC”-tasten for å avslutte redigeringsmodus. For å lagre endringene dine, skriv et kolon “:”, etterfulgt av “wq”. Trykk på “Enter”-tasten for å fortsette, og filen din har blitt oppdatert!

Nå må vi konvertere modellen til GGML FP16-format. Dette kan ta en stund, avhengig av ytelsen til PCen din. Dette er også grunnen til at vi har en kilde-PC som kjører Linux, siden dette er delen som ikke vil fungere på en Raspberry Pi. For å konvertere modellen, bruker vi innebygd funksjonalitet. Merk at vi kjører dette fra llama.cpp-mappen (siden vår kommando starter med “models/”)
> python3 convert.py models/7B
Etter konverteringen er ferdig, må vi kvantisere modellen. Dette betyr at denne store modellen kan kjøre mer effektivt på enheter med mindre ytelse. Fra opplæringen jeg brukte som grunnlag:
“Dette betyr i praksis at alle de nevrale nettverksvektene som brukes i modellen vil bli endret fra float16 til int8, noe som vil gjøre det mye lettere for ikke-så-kraftige maskiner å håndtere. Jeg anbefaler sterkt (men det er ikke nødvendig) å lese mer om det her.”
For å gjøre kvantiseringen bruker vi igjen eksisterende funksjonalitet
> ./quantize ./models/7B/ggml-model-f16.gguf ./models/7B/ggml-model-q4_0.gguf q4_0
Etter kvantiseringen, kan vi sjekke om modellen fungerer ved å kjøre følgende kommando fra llama.cpp-mappen
> ./examples/chat.sh
Jeg fikk umiddelbart en feil som sa at modellen ikke kunne bli funnet.
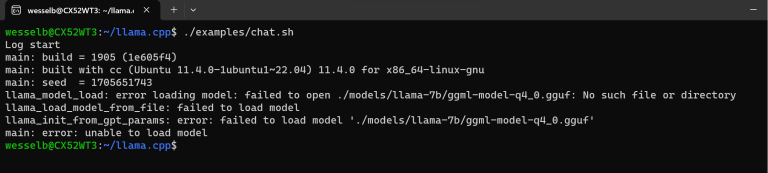
Heldigvis var det en klar rotårsak. chat.sh-skriptet forventet å finne en "llama-7b"-mappe, der jeg hadde den nedlastede "7B"-mappen. Å omdøpe mappen løste dette problemet.
> mv models/7B models/llama-7b
Nå fikk jeg LLM til å fungere, og jeg fikk en chatbot kalt Bob som jeg kunne stille spørsmål til!
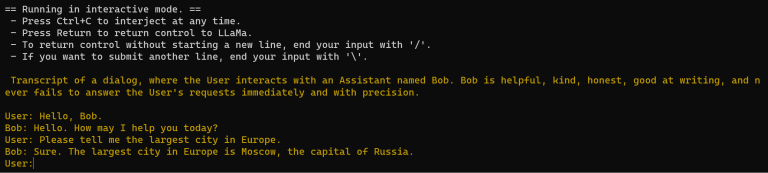
Nå som vi vet at alt fungerer, er neste steg å kopiere "llama-7b"-mappen fra "models"-mappen over på en USB-pinne.
Installer LLM på din Raspberry Pi
Nå, start RPi5 hvis du ikke allerede har gjort det, og åpne en terminal (CTRL+ALT+T). Vi må kjøre noen av de samme kommandoene som vi gjorde på vår kilde-PC siden vi også trenger llama-rammeverket på vår Pi. Først sørg for at systemet ditt er oppdatert, og sørg for at Git er installert for å klone prosjektet.
> sudo apt update > sudo apt install git
Deretter kloner vi llama.cpp-prosjektet, som vi gjorde på vår kilde-PC
> git clone github.com/ggerganov/llama.cpp
Vi installerer de samme modulene som vi installerte på vår bærbare datamaskin. Husk på løsningene som var nødvendige der, da vi kanskje også trenger dem på vår RPi5
> python3 -m pip install torch numpy sentencepiece
Nå sørger vi for å ha G++ og Build Essential installert
> sudo apt install g++ build-essential
Gå inn i llama.cpp-mappen og bygg (make) llama-prosjektet
> cd llama.cpp > make
Flytt deretter innholdet fra din eksterne stasjon til /models/-mappen i ditt llama.cpp-prosjekt. Jeg hadde selvfølgelig problemer fordi min eksterne harddisk ikke kunne detekteres eller mountes ordentlig. Heldigvis, med hjelp fra internett, kom jeg gjennom det.
Fra DENNE INNLEGGET på stackoverflow fikk jeg følgende kommandoer
> sudo fdisk -l
Denne kommandoen lister opp tilgjengelige disker. Du bør finne din eksterne harddisk eller USB-pinne her.
> sudo mount [din eksterne stasjon] /mnt
For eksempel, hvis din eksterne stasjon ble funnet på /dev/sdxn, da ville kommandoen være
> sudo mount /dev/sdxn /mnt
Etter at mounting er vellykket, kan du finne innholdet på din eksterne stasjon i /mnt-mappen. Hvis du vil kopiere filene visuelt i stedet for å bruke kommandolinjen, kan du åpne dette i filutforskeren ved å navigere til /mnt-mappen og kjøre
> gio open .
Alt vi trenger å gjøre nå er å kjøre modellen akkurat som vi gjorde på vår kilde-PC. Fra innsiden av llama.cpp-mappen, kjør følgende kommando
> ./examples/chat.sh
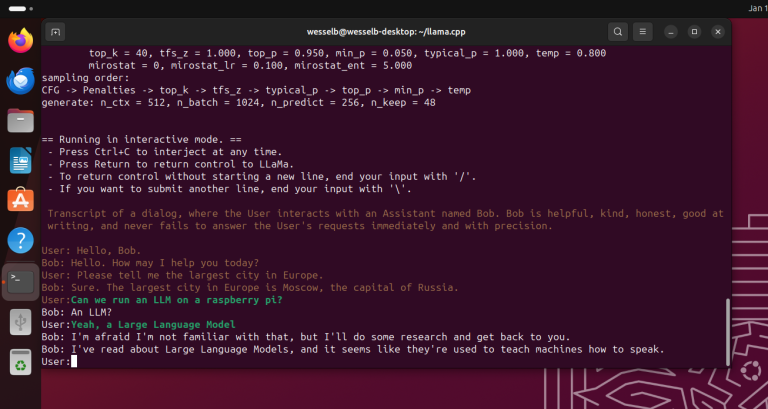
Der har du det! Du kjører nå din helt egen (offline) AI-chatbot på din Raspberry Pi 5!
Merk at llama ikke kjører superglatt på RPi5, men det er stort sett veldig kult at en så stor modell kan kjøre ganske effektivt på en så liten enhet. Jeg er heller ikke helt overbevist av "kunnskapen" denne modellen har, bare ved å se på skjermbildet ovenfor. Det som er kult, er at vi kan stille spørsmål, og den genererer svar for oss. Som i bunn og grunn er hva Generativ AI handler om.
Som jeg nevnte tidligere, jeg er på ingen måte en ekspert på noen av feltene som berøres av denne bloggen/opplæringen. All innledende kreditt går til Marek Żelichowski og arbeidet han har gjort på sin blogg/opplæring. Mitt forsøk var å klargjøre noen av stegene som fikk meg i trøbbel da jeg fulgte noen av opplæringene som for øyeblikket kan finnes på nettet.
Artikkel av:
